How to Parse Parley Data from Parler
How to parse out information from ‘Parleys’ to analyze data from the social media site, Parler.

In this post, I will demonstrate how to parse data from parleys from the social media site Parler for analysis. For this exercise, I will be using Python and the data recently scrapped from Parler following the January 6th events at the U.S. Capitol (which is available here).
What is Parler?
For those who don’t know, Parler is a social media platform that is “built upon a foundation of respect for privacy and personal data, free speech, free markets, and ethical, transparent corporate policy.” It is also known to have a significant number of posts that contain far-right content, antisemitism, and conspiracy theories such as QAnon, and so it is a valuable source of research material for those interested in studying these phenomena
The Parley
Parler users generally communicate with each other through the use of the ‘parley.’ These parleys act like a post on any other social media website and can receive upvotes, comments, or be echoed (which is similar to a re-tweet or quote on Twitter). The content of a parley can include many things, such as text, images, multi-media data, and links to outside websites. All of these elements of the parley are rendered as an HTML page. The following image gives an example of a parley from the data set used in this post

Parsing Out Data from the Parley
Since the parleys are HTML, we are going to have to go through the various tags within the parley to extract out the important information. For inspecting the HTML, I used Chrome’s Developer Tools. We will begin with importing some code that will be used throughout the parsing.
import re, pandas as pd
from bs4 import BeautifulSoup
from zipfile import ZipFileNext, we will go through each of the parleys and craft code to get out the important elements. First, we note that nearly all of the parley content is contained within a division of the class:
<div class=‘card card — post-container w — 100’>Everything outside of that division is just a standard Parler header and footer. To begin parsing all of the parleys, we first open the directory containing the parleys (in this case, a zipped file), create a list of the files in the directory, and then start reading each file into BeautifulSoup for parsing HTML. We will store out the various data elements from the parleys into a Python dict object.
with ZipFile(zipped_files, 'r') as f:
file_list = f.namelist()
for i in range(len(file_list)):
post = BeautifulSoup(f.read(file_list[i]),'html.parser')
parsed_post = {}
parsed_post['id'] = file_list[i]Now, we will start with parsing out the user account information. For any given Parley, we can have both user information about the original parley and about the user echoing the parley (if it is an echo). The author information consists of two elements, an ‘author name’ which is a free-text name a user can give themselves, and an ‘author user name’ which is the unique user name for a user (i.e. their ‘@’ name or handle).

The following block of code first checks to see if there is an author name — as sometimes you can get a bad scrape of the parley and this data is lost — and then parses this information out.
try:
parsed_post['author_user_name'] = post.find_all("span", {'class': "author--username"})[0].string
parsed_post['author_name'] = post.find_all("span", {'class': "author--name"})[0].string
except:
continueNext, we want to get out all of the echoing information, if this is an echoed parley. In particular, we would like to get out the echo author information, when it was echoed, and if the echo author gave any additional echoing text (like a quote on Twitter).
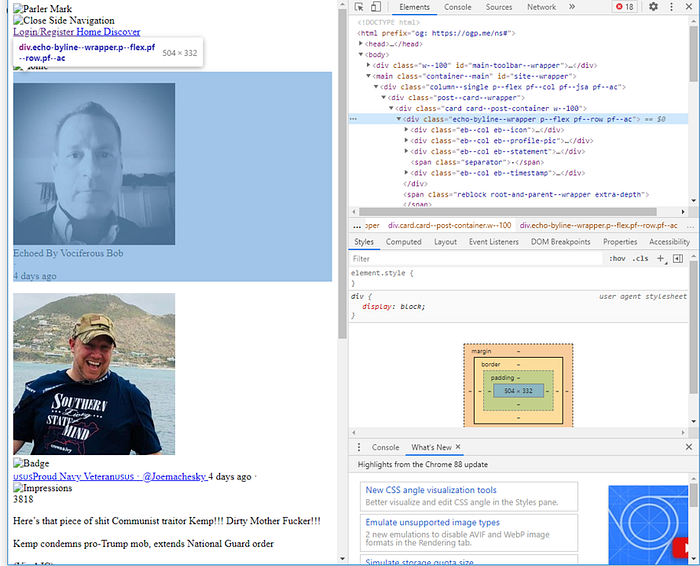
The following code parses out all of the echo information from the Parley. You’ll notice that the echo author’s user name is not actually in the echo block, but it can be found in the HTML title section.
echoed = post.find_all("div", {'class': "eb--col eb--statement"})
if len(echoed) >0:
parsed_post['echoed_by_author'] = list(echoed[0].children)[1].string[10:]
parsed_post['echoed_by_author_user_name'] = post.title.get_text().split()[0]
echoed_time = post.find_all("div", {'class': "eb--col eb--timestamp"})
parsed_post['when_echoed'] = list(echoed_time[0].children)[1].string
echo_comment = post.find("span", {'class': "reblock post show-under-echo"})
if echo_comment is not None:
parsed_post['echo_comment'] = echo_comment.find("div", {"class": 'card--body'}).get_text().strip()
else:
parsed_post['echoed_by_author'] =None
parsed_post['echoed_by_author_user_name'] = None
parsed_post['when_echoed'] =NoneHaving obtained the user and possible social network (i.e. who echoes whom) data from the parley, we now turn to the content data of the parley. In particular, we would like to parse out any text data, the impressions count of the parley (which is how many news feeds the parley was placed in), and any social media artifacts like hashtags or mentions.
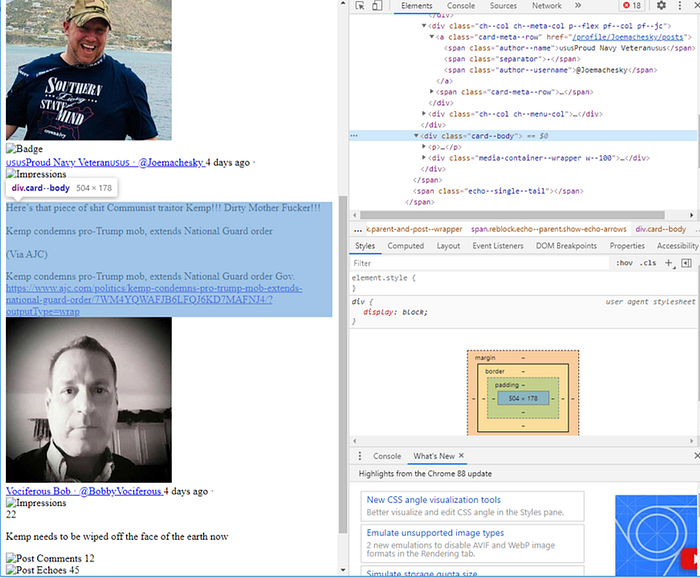
The following code parses out the content and also parses out any mentions or hashtags if they occur in the text.
parsed_post['impressions_count'] = int(post.find_all("span", {'class': "impressions--count"})[0].string)
main_body = post.find("div", {'class': "card--body"})
parsed_post['text'] = main_body.p.get_text()
parsed_post['hashtags'] = re.findall("#(\w+)", parsed_post['text'])
parsed_post['mentions'] = re.findall("@([a-zA-Z0-9]{1,15})", parsed_post['text'])Now, another important part of the content is the media content, such as images or video, and any external websites being shared in the Parley. Each of these types of external content has different HTML tags associated with them. So, we will need to check for each of the different types of content tags and parse out that content if it exists. In our example Parley, we have an external website being shared.
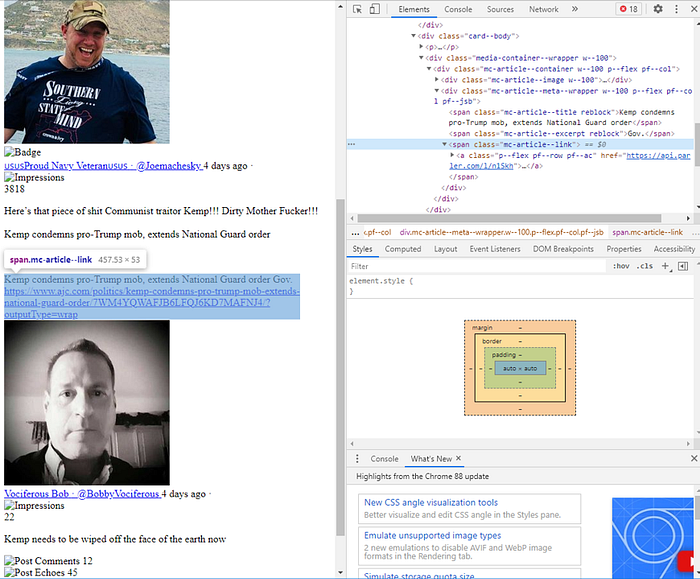
The following code will check if there is any image, media, or external websites being shared in the parley and then parse those out.
external_urls =[]
externals = post.find_all("span", {'class': "mc-article--link"})
externals = externals + post.find_all("span", {'class': "mc-iframe-embed--link"})
externals = externals + post.find_all("span", {'class': "mc-website--link"})
if len(externals) > 0:
for url in externals:
external_urls.append(list(url.a.children)[-1].strip())parsed_post['external_urls'] = external_urls
image_urls =[]
images = post.find_all("div", {'class': "mc-image--wrapper"})
if len(images) > 0:
for image in images:
image_urls.append(image.img['src'])
parsed_post['internal_image_urls'] = image_urls
media_urls =[]
video_hashes =[]
medias = post.find_all("span", {'class': "mc-video--link"})
if len(medias) > 0:
for media in medias:
media_urls.append(list(media.a.children)[-1].strip())
video_hashes.append(media_urls[-1].split('/')[-1].replace('.mp4', ''))parsed_post['internal_media_urls'] = media_urls
parsed_post['internal_video_hash'] = video_hashes
Note that I also parse out the hashes with the media links. These same hashes can be used with the media data set that comes with these parleys in order to link any scraped media data back to its parleys.
Finally, we also want to get out the meta-data about the Parley, like its upvotes and number of comments. Note, that while this data set does have the count of comments on a Parley, it does not actually have the comments themselves. This is just a limitation of this data set and maybe something to explore in the future.
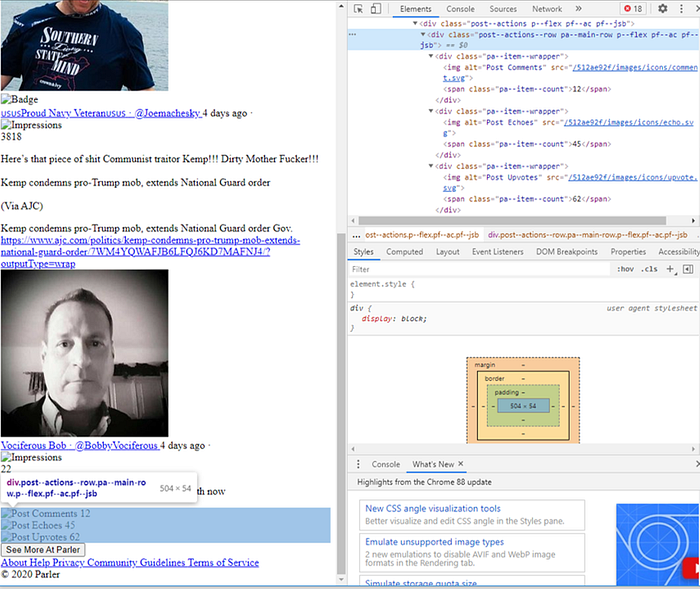
The following code can be used to parse the footer information for the ancillary information about the parley. Note, that sometimes the scrapes of the parleys miss this information, so I have wrapped it in a try-except block.
footer =post.find("div", {'class': "post--actions--row pa--main-row p--flex pf--ac pf--jsb"})
try:
footer_counts = footer.find_all("span", {'class': "pa--item--count"})
parsed_post['comments_count'] = int(footer_counts[0].string)
parsed_post['echoes_count'] = int(footer_counts[1].string)
parsed_post['upvotes_count'] = int(footer_counts[2].string)
except:
parsed_post['comments_count'] = None
parsed_post['echoes_count'] = None
parsed_post['upvotes_count'] = NoneHaving now established all of the necessary ingredients for parsing a parley, we can put everything together. Specifically, I choose to wrap all of the HTML-parsing into a generator function, which can then be feed to something like a Pandas DataFrame in order to get a nice, structured, analyzable version of all of your Parler posts. So, putting everything together, we have the following:
def parse_parler_archive(zipped_files):
with ZipFile(zipped_files, 'r') as f:
file_list = f.namelist()
for i in range(len(file_list)):
post = BeautifulSoup(f.read(file_list[i]), 'html.parser')
parsed_post = {}
parsed_post['id'] = file_list[i]
try:
'''
Check for a bad scrape
'''
parsed_post['author_user_name'] = post.find_all("span", {'class': "author--username"})[0].string
parsed_post['author_name'] = post.find_all("span", {'class': "author--name"})[0].string
except:
continue
parsed_post['timestamp'] = post.find_all("span", {'class': "post--timestamp"})[0].string
echoed = post.find_all("div", {'class': "eb--col eb--statement"})
if len(echoed) >0:
parsed_post['echoed_by_author'] = list(echoed[0].children)[1].string[10:]
parsed_post['echoed_by_author_user_name'] = post.title.get_text().split()[0]
echoed_time = post.find_all("div", {'class': "eb--col eb--timestamp"})
parsed_post['when_echoed'] = list(echoed_time[0].children)[1].string
echo_comment = post.find("span", {'class': "reblock post show-under-echo"})
if echo_comment is not None:
parsed_post['echo_comment'] = echo_comment.find("div", {"class": 'card--body'}).get_text().strip()
else:
parsed_post['echoed_by_author'] =None
parsed_post['echoed_by_author_user_name'] = None
parsed_post['when_echoed'] =None
parsed_post['impressions_count'] = int(post.find_all("span", {'class': "impressions--count"})[0].string)
main_body = post.find("div", {'class': "card--body"})
parsed_post['text'] = main_body.p.get_text()
parsed_post['hashtags'] = re.findall("#(\w+)", parsed_post['text'])
parsed_post['mentions'] = re.findall("@([a-zA-Z0-9]{1,15})", parsed_post['text'])
external_urls =[]
externals = post.find_all("span", {'class': "mc-article--link"})
externals = externals + post.find_all("span", {'class': "mc-iframe-embed--link"})
externals = externals + post.find_all("span", {'class': "mc-website--link"})
if len(externals) > 0:
for url in externals:
external_urls.append(list(url.a.children)[-1].strip())
parsed_post['external_urls'] = external_urls
image_urls =[]
images = post.find_all("div", {'class': "mc-image--wrapper"})
if len(images) > 0:
for image in images:
image_urls.append(image.img['src'])
parsed_post['internal_image_urls'] = image_urls
media_urls =[]
video_hashes =[]
medias = post.find_all("span", {'class': "mc-video--link"})
if len(medias) > 0:
for media in medias:
media_urls.append(list(media.a.children)[-1].strip())
video_hashes.append(media_urls[-1].split('/')[-1].replace('.mp4', ''))
parsed_post['internal_media_urls'] = media_urls
parsed_post['internal_video_hash'] = video_hashes
footer =post.find("div", {'class': "post--actions--row pa--main-row p--flex pf--ac pf--jsb"})
try:
footer_counts = footer.find_all("span", {'class': "pa--item--count"})
parsed_post['comments_count'] = int(footer_counts[0].string)
parsed_post['echoes_count'] = int(footer_counts[1].string)
parsed_post['upvotes_count'] = int(footer_counts[2].string)
except:
parsed_post['comments_count'] = None
parsed_post['echoes_count'] = None
parsed_post['upvotes_count'] = None
yield parsed_postzipped_files = '''path to your data'''
parler_data = pd.DataFrame(parse_parler_archive(zipped_files))
This code is also available on my GitHub page (https://github.com/ijcruic/Parse-Parler-Data). I hope you enjoyed the post and enjoy using Parler data in your research! -Crook
